
はじめに
Webアプリケーションを開発し、ユーザーに届けるバックエンドエンジニアにとって、ネットワークの知識は避けて通れません。
中でも「DNS」は、私たちが普段何気なく使っているインターネットの根幹を支える重要な技術です。
この記事では、「DNSって聞いたことはあるけど、正直よくわからない…」という若手バックエンドエンジニア の方に向けて、DNSの基本的な仕組みから、独自ドメインでWebサイトを公開する際の流れまで、体系的に解説します。
「なぜバックエンドエンジニアがDNSを知る必要があるの?」
その理由は明確です。
- 自分が開発したサービスが、なぜそのURLでアクセスできるのか説明できることは、サービスの仕組みを深く理解する上で重要だから
- インフラ担当者とネットワーク設定について話すとき、共通言語としてDNSの知識があると円滑にコミュニケーションできるから
- 「急にサービスに繋がらない!」といったトラブル発生時、原因がどこにあるか見当をつけるのに役立つから
このように、DNSの知識は、サービスの仕組みを深く理解し、他者と円滑に連携し、問題解決能力を高める上で不可欠なのです。
この記事の対象読者
- バックエンドエンジニア経験1〜3年目の方
- Webアプリケーション開発に携わっているが、インフラやネットワーク周りの知識に自信がない方
- DNSについて断片的な知識はあるが、体系的に学び直したい方
この記事のゴール
読み終える頃には、以下の状態になっていることを目指します。
- DNSの基本的な役割と仕組みを説明できる
- 独自ドメインでWebサイトが公開されるまでの大まかな流れを理解できる
専門用語も出てきますが、できるだけ図や具体例を交えながら、「バックエンドエンジニアとして最低限知っておきたいレベル」 を意識して解説していきます。
一緒にDNSの世界を探検しましょう!
DNSとは
スマートフォンの電話帳アプリのように、名前から番号を引く仕組みはインターネットにも存在します。
それがDNS (Domain Name System)です。
ホスト1には「192.0.2.1」のようなIPアドレスという番号が割り当てられています。
ホスト同士はこのIPアドレスで通信しますが、人間にとって数字の羅列は扱いにくいものです。
そこでDNSは、www.example.com のような人間が理解しやすいドメイン名と、コンピューターが通信に使うIPアドレスを対応付ける役割を担います。
つまり、DNSはドメイン名への問い合わせに対し、対応するIPアドレスを返すことで、人間とコンピューター間の橋渡しをしています。
この仕組みにより、私たちは覚えにくいIPアドレスを意識することなく、分かりやすいドメイン名を使って目的のWebサイトやサービスにアクセスできるのです。
ドメイン名の構造
DNSが扱うドメイン名は、一見すると単なる文字列ですが、実は世界中で名前が重複しないように、厳密なルールに基づいて管理されています。
この管理の仕組みを理解するために、まずはドメイン名の構造を見ていきましょう。
構造を表現する方法は色々ありますが、ドメイン名は階層構造が採用されています。
住所やディレクトリと同様です。www.example.com, example.com, sample.com, example.jpを表現したのが以下です。
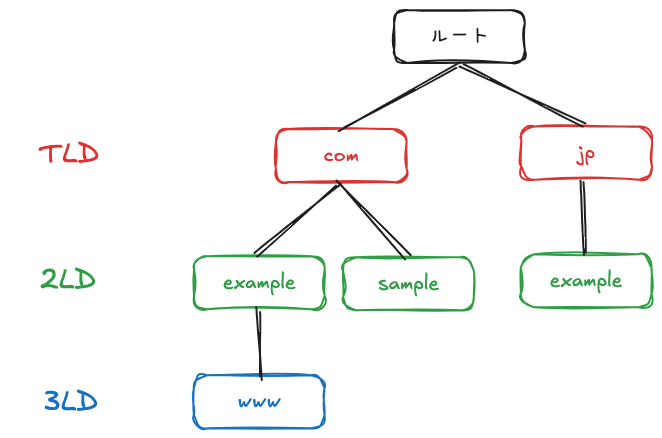
comやwwwなど各要素がドメイン、example.jpなど階層を「.(ドット)」で区切って右から左へ並べたものがドメイン名と呼ばれます。
各階層にも名前がついています。
- ルート: 階層構造の頂点です。すべてのドメイン名の末尾には本来
.が付いています。このことを知っているとルートの存在を意識しやすいでしょう。 - TLD (トップレベルドメイン): ドメイン名の最も右側の要素。
jpなど国や地域ごとに割り当てられるccTLDと、comなど国や地域によらないgTLDがあります。 - 2LD (セカンドレベルドメイン):
sampleなどTLDの次に位置するドメインです。 - 3LD (サードレベルドメイン): 考え方は2LDと同様です。
ドメインの管理体制
前のセクションでドメイン名が階層構造になっていることを学びましたが、ここで一つ疑問が浮かびます。
「世界中に無数にあるドメイン名は、一体誰が、どのように管理しているのだろうか?」
もし、一つの組織が全世界のドメイン名を管理しようとしたら、すぐにパンクしてしまいます。
そこでDNSでは、委任という仕組みを使って分散管理を実現しています。
委任とは、上位のドメイン (例えば.com) を管理する組織が、その下位のドメイン (例えばexample.com) の管理権限を、そのドメインを登録した組織に委ねることを指します。
委任された組織は、自身のドメインに関する情報2を管理する責任を負います。
管理を委任された組織は、自身のドメインに関する情報をネームサーバーと呼ばれるサーバーに設定し、インターネット上で公開します。
自身がさらに他の組織に委任している場合は、委任先のネームサーバーの情報も自身のネームサーバーに設定します。
このネームサーバーが、世界中からの「このドメイン名のIPアドレスは何?」という問い合わせに答える役割を果たします。
example.comを例に、ここまでの情報をまとめると以下のとおりです。
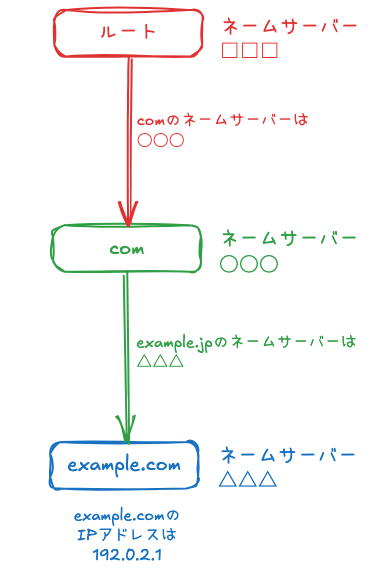
- ルートのネームサーバーには、委任先である
comのネームサーバーの情報が登録してある comのネームサーバーには、委任先であるexample.comのネームサーバーの情報が登録してあるexample.comのネームサーバーには、example.comドメイン名に対応するIPアドレスが登録してある
というわけです。
この管理体制において中心的な役割を担うのがレジストリとレジストラです。
- レジストリ: ドメイン名の一元管理を行う組織です。ひとつのTLDに対してひとつのレジストリが存在します。登録情報を蓄積し管理するレジストリデータベースを運用します。例えば、日本の
.jpドメインは「株式会社日本レジストリサービス (JPRS) 」が管理しています。 - レジストラ: ドメイン名登録者からの申請を取り次ぐ組織です。「お名前.com」や「ムームードメイン」などがこれにあたります。レジストリと直接やり取りできる事業者は限られており、多くの場合はレジストラを通じてドメイン名を申請・管理します。
ドメイン名の登録管理をこのように役割分担する仕組みをレジストリ・レジストラモデルといいます。
このように、DNSはドメイン空間を階層化し、各階層の管理権限を下位の組織に委任していくことで、世界規模の巨大な名前解決システムを効率よく、かつ安定的に運用しているのです。
独自ドメインでWebサイトを公開するまでの流れ
ここまでのセクションで、ドメイン名の仕組みや管理体制について学んできました。
では、実際に私たちが自分のWebサイトを独自ドメイン名 (例: my-awesome-site.com) で公開したい場合、裏側ではどのようなことが行われているのでしょうか?
ドメイン名を取得し、それを使ってWebサイトにアクセスできるようにするまでの大まかな流れを、「ドメイン名の登録」と「ドメイン名の利用設定」の2つのステップに分けて見ていきましょう。
ここでもレジストリ、レジストラ、そしてドメイン名を登録する私たち(登録者)が登場します。
ドメイン名を登録する
まずは、希望するドメイン名を使用する権利を確保します。
- 空き状況の確認: 使いたいドメイン名が他の人に使われていないか、レジストラ (お名前.comなど) のWebサイトで検索して確認します。
- レジストラの選択: ドメイン名を申請・管理してくれるレジストラを選びます。料金やサービス内容を比較検討しましょう。
- 申請情報の準備・提出: 選んだレジストラの指示に従い、ドメイン名の所有者となるための情報(氏名、住所、連絡先など)を正確に提出し、申請を行います。
- 申請内容の確認: 登録者から提出された情報に不備がないか確認します。
- レジストリへの登録申請: 確認後、そのドメイン名を管理するレジストリ (
.comならVerisign社など) に対して、レジストリデータベースへの登録を申請します。
- データベースへの登録: レジストラからの申請に基づき、レジストリデータベースにドメイン名と登録者情報を登録します。早い者勝ちなので、申請が重複した場合は先に受け付けた方が優先されます。
- 登録完了通知: 登録が完了したら、その旨をレジストラに通知します。レジストラは登録者に登録完了を伝えます。
これで、あなたは希望したドメイン名を使用する権利を得ました。
ドメイン名を使えるようにする
ドメイン名を登録しただけでは、まだその名前でWebサイトにアクセスすることはできません。
ドメイン名と、Webサイトが置かれているサーバーのIPアドレスを結びつける設定が必要です。
- ネームサーバーの準備: ドメイン名の情報を管理・応答するためのネームサーバーを用意します。通常、レンタルサーバーやクラウドサービス (AWS Route 53、Google Cloud DNSなど) が提供するネームサーバーを利用することが多いです。
- ネームサーバーへの情報設定: 用意したネームサーバーに、「
my-awesome-site.comのIPアドレスは192.0.2.10です」といった情報を設定します。 - 動作確認: 設定したネームサーバーが、ドメイン名に関する問い合わせに対して正しく応答するかどうかを確認します。
- ネームサーバー情報の申請: レジストラに対し、「
my-awesome-site.comについては、このネームサーバー(例:ns1.example-hosting.com)に問い合わせてください」という情報を設定するように申請します。通常、レジストラの管理画面から設定します。
レジストリへの設定申請: 登録者から申請されたネームサーバー情報を、レジストリデータベースに登録するようレジストリに申請します。
- データベースへの設定登録: レジストラからの申請に基づき、レジストリデータベースにネームサーバーの情報を登録します。
- レジストリのネームサーバーへの設定: レジストリ自身が管理するTLDのネームサーバー (
.comのネームサーバーなど) に、「my-awesome-site.comに関する問い合わせは、登録者が指定したネームサーバー (ns1.example-hosting.comなど) に聞いてください」という情報を設定します。これにより、委任が実現されます。
これが完了し、設定情報がインターネット全体に行き渡ると、世界中のどこからでもあなたのドメイン名を使ってWebサイトにアクセスできるようになります。
このように、独自ドメインでのWebサイト公開には、登録者、レジストラ、レジストリという三者の連携と、DNSの委任の仕組みが深く関わっているのです。
名前解決の流れ
私たちは毎日、ブラウザに example.com のようなURLを入力してWebサイトを見ています。
このとき、コンピューターはどのようにして目的のサーバーのIPアドレスを見つけ出しているのでしょうか?
この一連のプロセスを名前解決と呼びます。
ここでは、ドメイン名からIPアドレスを調べる正引きの流れを見ていきましょう。
この名前解決のプロセスには、いくつかの役割を持つサーバーが登場します。
- スタブリゾルバー: あなたが操作するPCやスマートフォンなどの機器で動作します。「私の代わりに名前解決をして、このドメイン名のIPアドレスを教えてください」と最初に問い合わせます。
- フルリゾルバー: スタブリゾルバーからの依頼を受け、目的のIPアドレスがわかるまで、他のネームサーバーに繰り返し問い合わせます。一度調べた結果はキャッシュとして一時的に保存し、次回以降の名前解決に利用します。
- 権威サーバー: 自分が委任を受けたゾーン3の情報と、自分が委任しているゾーンの委任情報を保持します。ネームサーバーのことです。
では、実際にブラウザに example.com と入力した際の、名前解決の舞台裏を見てみましょう。
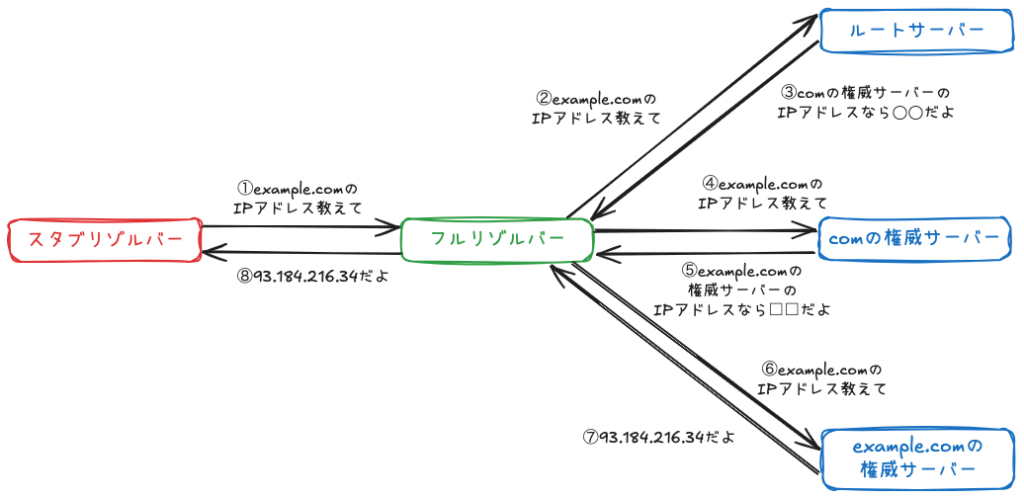
設定されているフルリゾルバーに「example.comのIPアドレスを教えて」と問い合わせます。
フルリゾルバーはまず、ルートサーバーに「example.comのIPアドレスを教えて」と問い合わせます。
ルートサーバーは「私自身は知らないけど、.comドメインのことなら、comの権威サーバーに聞いて」と、com権威サーバーのIPアドレスを返します。
フルリゾルバーは、教えてもらったcomの権威サーバーに「example.comのIPアドレスを教えて」と問い合わせます。
comの権威サーバーは「example.comドメインのことなら、example.comの権威サーバーに聞いて」と、example.comの権威サーバーのIPアドレスを返します。
フルリゾルバーは、ついに最終目的地である example.com の権威サーバーに「example.com のIPアドレスを教えて」と問い合わせます。
権威サーバーは、自身のゾーンデータ4の中から example.com に対応するIPアドレス (例: 93.184.216.34) を見つけ出し、「IPアドレスは 93.184.216.34 です」とフルリゾルバーに回答します。
最終的なIPアドレスを受け取ったフルリゾルバーは、そのIPアドレスをスタブリゾルバーに返します。
このIPアドレスを受け取ったWebブラウザは、目的のWebサーバー (IPアドレス 93.184.216.34) に対して、Webページのデータを要求するHTTPリクエストを送信できるのです。
このように、一見単純に見えるドメイン名からのアクセスですが、裏側ではネームサーバーたちが連携し、階層をたどって目的の情報を探し出す、というプロセスが実行されています。
リソースレコード
これまでのセクションで、権威サーバーがゾーンデータを保持していると説明しました。
このゾーンデータは、リソースレコードと呼ばれる形式で記述された情報の集まりです。
リソースレコードは、ドメイン名に関連付けられた様々な種類の情報を示す、DNSにおける情報の基本単位と言えます。
リソースレコードの基本構造
リソースレコードは、一般的に以下のようなフォーマットで記述されます。
<ドメイン名> <TTL> <クラス> <タイプ> <データ>それぞれのフィールドの意味を見ていきましょう。
- ドメイン名: 問い合わせで指定したドメイン名。例えば
www.example.com.のようになります。 - TTL (Time To Live): そのリソースレコードをキャッシュしてもよい時間が秒単位で入ります。
- クラス: ネットワークの種類を示します。インターネットで使われるDNSでは、通常
IN(Internet) が指定されます。 - タイプ: 情報の種類を示します。様々なタイプがありますが、詳細は後述です。
- データ: クラスやタイプによって異なる、リソースレコードのデータです。
代表的なリソースレコードのタイプ
それでは、代表的なリソースレコードのタイプを、上記のフォーマットを意識しながら見ていきましょう。
- Aレコード (Address)
- ドメイン名に対応するIPv4アドレスを指定します。
例:www.example.com. 3600 IN A 93.184.216.34
- ドメイン名に対応するIPv4アドレスを指定します。
- AAAAレコード (Quad A)
- ドメイン名に対応するIPv6アドレスを指定します。
例:www.example.com. 3600 IN AAAA 2606:2800:220:1:248:1893:25c8:1946
- ドメイン名に対応するIPv6アドレスを指定します。
- NSレコード (Name Server)
- そのゾーンの権威サーバーのホスト名を指定します。DNSの「委任」を実現します。
例:example.com. 86400 IN NS ns1.example.com.
- そのゾーンの権威サーバーのホスト名を指定します。DNSの「委任」を実現します。
- MXレコード (Mail Exchanger Record)
- そのドメイン名宛ての電子メールの配送先と優先順位を指定します。
例:example.com. 7200 IN MX 10 mail.example.com.
- そのドメイン名宛ての電子メールの配送先と優先順位を指定します。
これら以外にも様々なリソースレコードが存在しますが、まずはこの基本構造と代表的なレコードタイプを理解することが重要です。
ネームサーバーを設定する際には、これらのフィールドを意識してレコードを記述することになります。
処理の効率化と可用性の向上
DNSはインターネットの基盤であり、その応答速度や安定性はWebサイトの表示速度やサービスの信頼性に直結します。
そのため、DNSには応答を高速化し、停止しないようにするための重要な仕組みが備わっています。
それが「キャッシュ」と「冗長化」です。
キャッシュによる処理の効率化
「名前解決の流れ」で、フルリゾルバーが登場したのを覚えていますか?
フルリゾルバーは、一度問い合わせて得た名前解決の結果を、一定期間キャッシュとして内部に保存しています。
次に同じドメイン名への問い合わせが来た際には、わざわざ権威サーバーまで聞きに行かなくても、保存しておいたキャッシュから即座に応答を返すことができます。
これにより、名前解決にかかる時間を大幅に短縮し、ユーザーがWebサイトにアクセスする際の待ち時間を減らすことができます。
キャッシュが有効な期間は、権威サーバー側で設定されるTTLによって決まります。
TTLが切れると、フルリゾルバーは再度権威サーバーに問い合わせて最新の情報を取得し直します。
また、キャッシュにはネガティブキャッシュという仕組みもあります。
これは、「存在しないドメイン名」や「エラーになった問い合わせ」の結果も一定期間キャッシュするものです。
これにより、無効な問い合わせが繰り返し権威サーバーに送られるのを防ぎ、無駄な負荷を減らす効果があります。
冗長化による可用性の向上
もし、あるドメインの情報を管理する権威サーバーが1台しかなく、そのサーバーが故障やメンテナンスで停止してしまったらどうなるでしょうか?
そのドメインに関する名前解決が一切できなくなり、Webサイトへのアクセスやメールの送受信ができなくなってしまいます。
このような事態を防ぐために、権威サーバーは通常、複数台で運用され、冗長性が確保されています。
その代表的な構成がプライマリ/セカンダリ構成です。
- プライマリサーバー: 元となる権威サーバーです。
- セカンダリサーバー: プライマリサーバーから定期的にゾーンデータのコピーを受け取るサーバーです。
プライマリサーバーからセカンダリサーバーへゾーンデータをコピーする仕組みをゾーン転送と呼びます。
セカンダリサーバーは、ゾーン転送によってプライマリサーバーと同じ状態に保たれます。
通常、プライマリサーバー1台と、1台以上のセカンダリサーバーが設定されます。
これにより、プライマリサーバーが停止しても、セカンダリサーバーが代わりに応答を続けることができるため、DNSサービスが停止するリスクを大幅に低減できます。
これがDNSの可用性を高める基本的な考え方です。
このように、キャッシュによる処理の効率化と、冗長化による可用性の向上によって、DNSはインターネットの安定した運用を支えているのです。
まとめ
今回は、バックエンドエンジニアなら知っておきたいDNSの基礎について幅広く解説してきました。
この記事で学んだ重要なポイントを振り返ってみましょう。
- DNSは人間が理解しやすいドメイン名と、コンピューターが通信に使うIPアドレスを対応付ける役割を担います
- ドメイン名は階層構造を持ち、レジストリやレジストラといった組織によって委任されながら分散管理されています。
- 独自ドメインの公開には、登録者・レジストラ・レジストリが連携し、ドメイン登録とネームサーバー設定のステップが必要です。
- Webサイトへのアクセス時には、フルリゾルバーが権威サーバーへ問い合わせを繰り返し、目的のIPアドレスを突き止める名前解決が行われています。
- ネームサーバーにはリソースレコード (A, AAAA, NS, MXなど) が設定されます。
- キャッシュによる処理の効率化や、冗長化による可用性の向上といった仕組みが、DNSの安定運用を支えています。
DNSは普段あまり意識しないかもしれませんが、Webサービスが動作する上で不可欠な技術です。今回学んだ知識は、インフラ担当者とのコミュニケーションや、システムトラブル時の原因究明など、バックエンドエンジニアとしての業務できっと役立つはずです。
ぜひ、この基礎知識を足がかりに、さらに理解を深めていってください。
コメント